Reconstruction
Az oldal fordítása nem teljes
Common method for reconstructing the raw data for a cone-beam CT is the filtered back-projection (FBP) algorithm. This is an analytical procedure based on the assumption that the acquired projections are generated by radon transforming the linear attenuation factors for the whole volume. An analytical invers radon transformation can be used for the reconstruction. If the available projections are ideal, the FBP reconstruction is the same as the ideal reconstruction. For perfect reconstruction the following conditions must be satisfied :
- Monochromatic X-ray source and beam
- There is no scattered photon
- The object is not moving while the acquisition
- The whole object must be fit into the scanners Field of View (FOV)
- Infinity amount of projections are available for the reconstruction
- Noiseless raw CT data
- Linearity: the measured signal is direct proportional of the number of photons was detected, dynamic range: the detector is capable to detect only one photon or infinite number of photons
- Homogeneous detector elements
The theory of the Feldkamp-Davis-Kress type reconstruction (FDK) based on monochromatic x-ray beam. The attenuation in a homogenous object is described by the Lambert-Beer law:
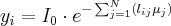
Previous chapters have more details about this. In „Practical cone-beam algorithm” paper there is more information about the FDK type reconstructions.
Normalising the projection images
FBP algorithm starts with normalising the raw CT projection images:
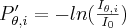
where 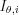 is the intensity of a detector pixel for a given
is the intensity of a detector pixel for a given  angle and the index of the detector element,
angle and the index of the detector element, 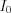 is the base intensity of the x-ray source. is measured for all x-ray energies and exposition times as a calibration step. During this calibration there is no object between the source and the detector.
is the base intensity of the x-ray source. is measured for all x-ray energies and exposition times as a calibration step. During this calibration there is no object between the source and the detector.
Filtering the images
The FDK algorithm is basically a filtered back-projection that applies a filter in the frequency domain before back-projecting the projection images. The mathematical derivation prescribes the RAMP (a.k.a. RamLak) filter which suppresses the low frequency components but raises the high frequency parts of the signal. In practice this filter gives suboptimal noise performance because the highest frequencies often do not contain useful information and the high frequency edge of the filter behaves badly during the discrete inverse Fourier transform. We can combine the RAMP filter with several window functions for filtering the high frequency components. There are some well-known window functions for the back-projection operator of a CT reconstruction. The new filters named after the window function are simply the product of the original RamLak filter and a window function (see Figure 8). We must care about the balance between resolution and noise they are definitely on the resolution side (see Figure 9). We can categorize the filters into three groups:
High-resolution filters:
- RamLak:
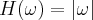
- Butterworth:
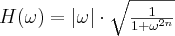
- Shepp-Logan:
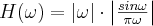
For the most common cases we suggest to use the Shepp-Logan filter as it reduces the noise by at least 10% while the resolution is almost 96% of the RamLak filtered image. The Butterworth filter has even less adverse effect on the resolution while still improving noise performance
In the second group there are the:
- Cosine:
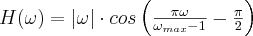
- Hamming:
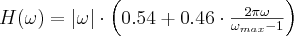
- Hann:
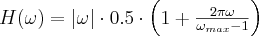
The noise reduction of these filters is better than that of the high-resolution filters; on the other hand the resolution is also reduced.
We experimented with several low-resolution filters but decided to keep only the Blackman filter. Low-resolution filters cut off not only the noise but also reduce the resolution significantly. With the Blackman filter the noise is about the 60%, the resolution is proximately 75% of the RamLak filtered image. The BlackMan is useful for some calibration protocols only.
Figure 8 The characteristics of the different filters. Horizontal axis represents the frequencies from 0 (base frequency) to 1 (highest frequency). Vertical axis represents the gain (multiplier) for the current frequency.
Figure 9 Correlation between the resolution and the noise for different filters. Horizontal axis: standard deviation of water in Hounsfield units (smaller numbers represents better quality). Vertical axis: resolution (MTF- bigger numbers represents better quality)
Backprojection
The filtered projection images have to be back-projected to the target volume. Currently there are three different approaches for back-projection (BP): pixel- , distance- and voxel-driven .
In the first case rays are generated from the detector pixels. They go through the whole volume and the contribution of the current pixel to the voxels among the actual ray is calculated.
Figure 10 Pixel-driven back-projection schema
The pixels of the projection image are normalized by function: 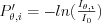 , and the image is filtered:
, and the image is filtered: 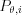 by the selected filter (see previous section). . The incremental voxel value for the current projection (at angle) is:
by the selected filter (see previous section). . The incremental voxel value for the current projection (at angle) is:
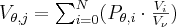
where 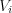 is the volume of the section of the voxel and the “ray-pyramid” and
is the volume of the section of the voxel and the “ray-pyramid” and 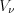 is the volume of the voxel. In 3D the base of the “ray-pyramid” is the current detector pixel, and the zenith is the focus point of the X-ray source. In Figure 10 the two dimensional case is presented for simplicity; blue and yellow areas represent sections of the “ray-pyramids”. In practice the sections are usually approximated by starting several rays from each pixel. The calculations are still complex and have to be repeated for each projection image, which makes the algorithm slow. Another disadvantage of this method is that its implementation for GPU is not efficient, because there can be write collision in the GPU memory when writing back the calculated (incremental) value of the voxel. The implementation is possible by using atomic operations (e.g. atomic add) but that significantly slows down the reconstruction speed.
is the volume of the voxel. In 3D the base of the “ray-pyramid” is the current detector pixel, and the zenith is the focus point of the X-ray source. In Figure 10 the two dimensional case is presented for simplicity; blue and yellow areas represent sections of the “ray-pyramids”. In practice the sections are usually approximated by starting several rays from each pixel. The calculations are still complex and have to be repeated for each projection image, which makes the algorithm slow. Another disadvantage of this method is that its implementation for GPU is not efficient, because there can be write collision in the GPU memory when writing back the calculated (incremental) value of the voxel. The implementation is possible by using atomic operations (e.g. atomic add) but that significantly slows down the reconstruction speed.
The distance-driven (DD) projector is a current state-of-the-art method. It maps the horizontal and vertical boundaries of the image voxels and detector cells onto a common plane such as xz or yz plane, approximating their shapes by rectangles. It calculates the lengths of overlap along the x (or y) direction and along the z direction, and then multiplies them to get the area of overlap (see Figure 11).
Figure 11 Distance-driven back-projection schema
The voxel-driven (a.k.a. ray-driven 9, 10) method generates rays from the focal point of the X-ray source through the voxels. The projection is independent for each voxel, making a parallel implementation that suits for the GPU architecture straightforward. The difficult part of the algorithm is to calculate the footprint of the voxels. This is a function generated by projecting the 3D voxel onto the detector surface at a given angle (see Figure 12):
Figure 12 Voxel-driven back-project schema with voxel footprint
For a given angle we define the 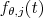 footprint function, where j is the index of a voxel and t is a point on the detector. The incremental voxel value for the angle is:
footprint function, where j is the index of a voxel and t is a point on the detector. The incremental voxel value for the angle is:
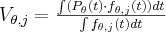
where 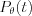 function is the logarithmically normalized and filtered value of the detector at point t, the integrals are calculated for the full detector surface. The value of a voxel is the sum of all the incremental values of the voxel calculated for all detector angles (similarly to the pixel-driven method). Unfortunately this quasi exact solution gives a rather slow algorithm. This integration can be approximated by sampling if we choose the distribution of the sampling points proportional to the current integrand (Monte-Carlo integration ). Furthermore if we are sampling a voxel with a homogeneous distribution, the projections of these points will represent the necessary distribution (see Figure 13). Calculation of the incremental voxel value now simplifies to the following equation:
function is the logarithmically normalized and filtered value of the detector at point t, the integrals are calculated for the full detector surface. The value of a voxel is the sum of all the incremental values of the voxel calculated for all detector angles (similarly to the pixel-driven method). Unfortunately this quasi exact solution gives a rather slow algorithm. This integration can be approximated by sampling if we choose the distribution of the sampling points proportional to the current integrand (Monte-Carlo integration ). Furthermore if we are sampling a voxel with a homogeneous distribution, the projections of these points will represent the necessary distribution (see Figure 13). Calculation of the incremental voxel value now simplifies to the following equation:
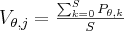
where is S the number of sampling points and 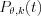 is the normalized filtered pixel value for the sample point k. How can we choose the best sampling method? We can use a regular three dimensional grid inside the voxel. It is a very simple method but if we use some low-discrepancy sequence we can reach more uniform distribution. With Poisson Disk sampling we have achieved lower noise levels with only half of the points we used for regular sampling. Moreover with quasi-random sampling we can avoid the Moiré effect which is the most common artefact of the voxel-driven BP. Generating the PD samples is very computation intensive, but it can be done offline. So we have generated a couple of sample point sets offline and later simply choose one for a selected projection. With this multi-sampled voxel-driven BP we can significantly suppress the noise without lowering the resolution.
is the normalized filtered pixel value for the sample point k. How can we choose the best sampling method? We can use a regular three dimensional grid inside the voxel. It is a very simple method but if we use some low-discrepancy sequence we can reach more uniform distribution. With Poisson Disk sampling we have achieved lower noise levels with only half of the points we used for regular sampling. Moreover with quasi-random sampling we can avoid the Moiré effect which is the most common artefact of the voxel-driven BP. Generating the PD samples is very computation intensive, but it can be done offline. So we have generated a couple of sample point sets offline and later simply choose one for a selected projection. With this multi-sampled voxel-driven BP we can significantly suppress the noise without lowering the resolution.
Figure 13 Multi-sampled voxel-driven back-project schema with voxel footprint
Hounsfield correction
Final step of the reconstruction is normalizing the voxel values to a standard scale. This method is known as Hounsfield correction. The CT detector measures the linear attenuation factor, but the Hounsfield scale represents the relative attenuation of the water in Hounsfield Units (HU).
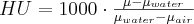
where
µ the attenuation factor for the selected material
µwater is the attenuation factor of the water for the x-ray energy used for CT scan
µair is the attenuation factor of the air for the x-ray energy used for CT scan
Hardware architectures
Although the filtered back-projection algorithm is one of the fastest reconstruction methods, when trying to increase the image quality and the resolution a huge computing capability is necessary otherwise the reconstruction time will be enormous. When the target volume size is 10243 voxels, the reconstruction can run for hours even if we have a modern multicore CPU. For achieving the necessary computing performance usually used computer clusters, but these systems not only very expensive but needs a lot of space and electric power. An alternative way is using special, dedicated hardware for example FPGA cards for the reconstruction, but the development time for these unique hardware is very big.
Fortunately, the graphics card (GPU) is an essential component of all modern computers, which used for games and 3D applications (e.g. CAD software). The GPUs in the last few years reached a stage when it can be used for accelerating general algorithms (General Purpose GPU - GPGPU). In research and development GPUs are used for wide range of algorithms e.g. financial, medical applications, weather forecast, oil industry. Computing power of a modern GPU (Nvidia GTX-580) is about 1500 GFLOPS, while a high-end CPU (Intel 980X) is only capable of 65 GFLOPS. In practical case that means a common PC with several common GPUs can outperforms a CPU cluster .
Iterative reconstruction methods
Most of the artefacts of the reconstruction algorithm are caused by an ineligible system model used for the reconstruction (difference from a real measured data). Therefore, using a more accurate mathematical model can reduce or eliminate the artefacts.
There are two main types of the iterative reconstruction methods: Algebraic Iterative Reconstruction (ART) and Statistical Iterative Reconstruction (SR) (see Figure 14). Both of them are significantly increase the computing time comparing to the traditional FBP, however, better image quality can be reached and these methods less sensitive to defects caused by the acquisition, e.g. noise, limited number of projections.
Figure 14 Types of reconstruction methods
In the algebraic approach the reconstruction is simply solving equations derived from the physical system matrix. Unfortunately the number of variables in this equation system is equal the number of voxels in the volume and it can be billions. This system can only be solved with iterative methods. This method is mostly used for PET and SPECT devices with much smaller datasets.
Most publications are about another kind of iterative algorithms; these are called statistic iterative reconstructions. Using a mathematical model for the noise characteristic in the reconstruction the noise can be suppressed. This method is less sensitive to incomplete data in raw projection images. Since it is not necessary to specify the explicit form of imaging used in the acquisition, the inverse transformation can be used for a wide range of geometries. Moreover the algorithmic artefacts like beam-hardening, metal artefacts, scattering can be reduced or even eliminated. In practical cases that mean better image quality or lower dose can be used for scanning.
The only real downside is still counting the 2-3 orders of magnitude higher computing time for reconstruction. However, a lot of research focuses on speeding up these methods. Modified algorithms are developed to implement algorithms for specific hardware (e.g. GPUs) and multi-computer networks (clusters).
The general scheme of the iterative reconstruction algorithms is the following (see Figure 15):
Figure 15 General scheme of the iterative reconstruction algorithms
Before the first iteration an initial CT image have to be generated. This can be generated by an FBP algorithm or can be a simple void image. While each step of the reconstruction a simulated projection image is created using the results of the pervious iteration. After that the simulated and the measured projection image has to be compared and an error image is generated. Using this error image we can correcting the reconstructed images, and continue the iterations to the next step.
Sidebar
Site Language: English
Theme: Tikinewt