The ML-EM algorithm
A Maximum-Likelihood Expectation Maximisation (ML-EM method)
The basic idea behind the ML-EM method is that the pdf of the measured data may not contain -let's say- the pdf of missing measurements that would influence the estimation decisively. This missing information may be estimated iteratively, and for each of this steps we also carry out an ML-estimation. We could think of e.g. that some part of the data has connection to only some parameters and other parts of the data to an independent other group. If we knew which date belonged to which group we could produce far better estimates to the parameters. The E-step of the ML-EM method tries to take into account the effect of this missing parameter without providing an explicit estimate to it.
Let us assume that the measured y data can be completed to an s data vector that contain the missing information. Then we can set up a statistical model with the following pdf: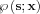
The ML-EM method iterates by repeating the following steps
1) The E (Expectation) step
Using the parameter estimate in the n. iteration xn using the statistical model we can calculate the likelihood-function with the following conditional pdf for every possible x parameter:
![$ Q\left ( \mathbf{x},\mathbf{x}^{n} \right )=E\left [\wp \left ( \mathbf{s}; \mathbf{x} \right )\mid\mathbf{y} ;\mathbf{x}^{n} ]](lib/equation/pictures/fe1c16f86a2a655fd64520fda4c79f6c.png)
2) The M (Maximization) step
With the obtained likelihood function we take a regular ML step:
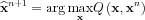
The convergence of the ML-EM method
The question naturally arises that if we cannot measure the missing data where does the extra information come in that makes our estimate better?
The answer is in the modelling itself, by applying a more sophisticated modeling may improve the results. We have to prove first that the inclusion of this extra modeling will at least not spoil the convergence of our previous estimation. Let us write the pdf of the completed data set using the Bayes theorem:
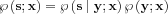
Now the log-likelihood function:
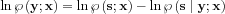
Let us look at how the log-likelihood function changes after the E and M steps where the expected value is taken regarding the s random variable:
![$ E\left [\ln \wp \left ( \mathbf{y} ; \mathbf{x} \right ) \right \mid\mathbf{y} ;\mathbf{x}^{n} ]=\underbrace{E\left [\ln \wp \left ( \mathbf{s}; \mathbf{x} \right ) \mid\mathbf{y} ;\mathbf{x}^{n} \right ]}_{Q\left ( \mathbf{x},\mathbf{x}^{n} \right )}-\underbrace{E\left [\ln \wp \left ( \mathbf{s}\mid\mathbf{y} ; \mathbf{x} \right ) \mid\mathbf{y} ;\mathbf{x}^{n} \right ]}_{R\left ( \mathbf{x},\mathbf{x}^{n} \right )}](lib/equation/pictures/03b13878441a8ada39137f48445d68f5.png)
The LHS does not contain s, its expected value is itself. Let us look at how the log-likelihood changes between iteration steps n. and n+1. if we fill in the estimated values:
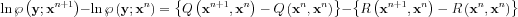
If the M step maximized 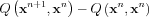 successfully, then the difference with the filled values is positive. The expected value of the second term can be estimated using the following identity:
successfully, then the difference with the filled values is positive. The expected value of the second term can be estimated using the following identity:
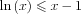
thus:
![$ R\left ( \mathbf{x}^{n+1},\mathbf{x}^{n} \right )-R\left ( \mathbf{x}^{n},\mathbf{x}^{n} \right ) =E\left [\frac{
\ln \wp \left ( \mathbf{s}\mid\mathbf{y} ; \mathbf{x}^{n+1} \right )}{\ln \wp \left ( \mathbf{s}\mid\mathbf{y} ; \mathbf{x}^{n} \right )} \mid\mathbf{y} ;\mathbf{x}^{n} \right]\leqslant \int \frac{
\ln \wp \left ( \mathbf{s}\mid\mathbf{y} ; \mathbf{x}^{n+1} \right )}{\ln \wp \left ( \mathbf{s}\mid\mathbf{y} ; \mathbf{x}^{n} \right )}\ln \wp \left ( \mathbf{s}\mid\mathbf{y} ; \mathbf{x}^{n} \right )d\mathbf{s}-1=0](lib/equation/pictures/d3cfed35af35a4e3e24cc1521f92f08d.png)
so the E and M steps result in a negative change of R
We have proven that
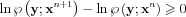
This ensures that the algorithm will not deteriorate the ML estimate at least
In the next section we discuss the ML-EM algorithm for emission tomography.
The original document is available at http://549552.cz968.group/tiki-index.php?page=The+ML-EM+algorithm